INTRODUCCION A BD

¿Qué es una base de datos?
Una base de datos es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso. En este sentido; una biblioteca puede considerarse una base de datos compuesta en su mayoría por documentos y textos impresos en papel e indexados para su consulta. Actualmente, y debido al desarrollo tecnológico de campos como la informática y la electrónica, la mayoría de las bases de datos están en formato digital, siendo este un componente electrónico, por tanto se ha desarrollado y se ofrece un amplio rango de soluciones al problema del almacenamiento de datos.
Existen programas denominados sistemas gestores de bases de datos, abreviado SGBD (del inglés Database Management System o DBMS), que permiten almacenar y posteriormente acceder a los datos de forma rápida y estructurada. Las propiedades de estos DBMS, así como su utilización y administración, se estudian dentro del ámbito de la informática.
Las aplicaciones más usuales son para la gestión de empresas e instituciones públicas; También son ampliamente utilizadas en entornos científicos con el objeto de almacenar la información experimental.
Diferencia entre dato e información:
Lo primero que debemos tener claro es qué es cada término, a continuación lo describiremos de la mejor manera posible.
- Un dato no es otra cosa que una representación simbólica de alguna situación o conocimiento, sin ningún sentido semántico, describiendo situaciones y hechos sin transmitir mensaje alguno. Puede ser un número, una letra o un hecho.
- Mientras que la información, es un conjunto de datos, los cuales son adecuadamente procesados, para que de esta manera, puedan proveer un mensaje que contribuya a la toma de decisión a la hora de resolver un problema, además de incrementar el conocimiento, en los usuarios que tienen acceso a dicha información.
A continuación les vamos a presentar las principales diferencias entre dato e información.
- Los datos son utilizados por lo general, para comprimir información con la finalidad de facilitar el almacenamiento de datos, y su transmisión a otros dispositivos. Al contrario que la información, la cual tiende a ser muy extensa.
- La información o mensaje es mucho mayor que los datos, ya que la información se encuentra integrada por un conjunto de datos de diferentes tipos.
- Otra característica destaca-ble de la información, es que es un mensaje que tiene sentido comunicacional y una función social. Mientras que el dato, no refleja mensaje alguno y por lo general, es difícil de entender por sí solo para cualquier ser humano, careciendo de utilidad si se encuentra aislado o sin otros grupos de datos que creen un mensaje coherente.
Conclusión
Como podemos ver, la principal diferencia se centra en el mensaje que puede transmitir la información, y que un dato por sí solo no puede realizar. Se necesitan muchos datos para crear un mensaje o información.
12 reglas de Codd y para qué sirven.
Codd se percató de que existían bases de datos en el mercado las cuales decían ser relacionales, pero lo único que hacían era guardar la información en las tablas, sin estar estas tablas literalmente normalizadas; entonces éste publicó 12 reglas que un verdadero sistema relacional debería tener aunque en la práctica algunas de ellas son difíciles de realizar. Un sistema podrá considerarse “más relacional” cuanto más siga estas reglas.
Regla 0: el sistema debe ser relacional, base de datos y administrador de sistema. Ese sistema debe utilizar sus facilidades relacionales (exclusivamente) para manejar la base de datos.
– Regla 1: la regla de la información, toda la información en la base de datos es representada unidireccionalmente, por valores en posiciones de las columnas dentro de filas de tablas. Toda la información en una base de datos relacional se representa explícitamente en el nivel lógico exactamente de una manera: con valores en tablas.
– Regla 2: la regla del acceso garantizado, todos los datos deben ser accesibles sin ambigüedad. Esta regla es esencialmente una nueva exposición del requisito fundamental para las llaves primarias. Dice que cada valor escalar individual en la base de datos debe ser lógicamente direccionable especificando el nombre de la tabla, la columna que lo contiene y la llave primaria.
– Regla 3: tratamiento sistemático de valores nulos, el sistema de gestión de base de datos debe permitir que haya campos nulos. Debe tener una representación de la “información que falta y de la información inaplicable” que es sistemática, distinto de todos los valores regulares.
– Regla 4: catálogo dinámico en línea basado en el modelo relacional, el sistema debe soportar un catálogo en línea, el catálogo relacional debe ser accesible a los usuarios autorizados. Es decir, los usuarios deben poder tener acceso a la estructura de la base de datos (catálogo).
– Regla 5: la regla comprensiva del sublenguaje de los datos, el sistema debe soportar por lo menos un lenguaje relacional que:
- Tenga una sintaxis lineal.
- Puede ser utilizado de manera interactiva.
- Soporte operaciones de definición de datos, operaciones de manipulación de datos (actualización así como la recuperación), seguridad e integridad y operaciones de administración de transacciones.
– Regla 6: regla de actualización, todas las vistas que son teóricamente actualizables deben ser actualizables por el sistema.
– Regla 7: alto nivel de inserción, actualización, y cancelación, el sistema debe soportar suministrar datos en el mismo tiempo que se inserte, actualiza o esté borrando. Esto significa que los datos se pueden recuperar de una base de datos relacional en los sistemas construidos de datos de filas múltiples y/o de tablas múltiples.
– Regla 8: independencia física de los datos, los programas de aplicación y actividades del terminal permanecen inalterados a nivel lógico cuando quiera que se realicen cambios en las representaciones de almacenamiento o métodos de acceso.
– Regla 9: independencia lógica de los datos, los cambios al nivel lógico (tablas, columnas, filas, etc.) no deben requerir un cambio a una solicitud basada en la estructura. La independencia de datos lógica es más difícil de lograr que la independencia física de datos.
– Regla 10: independencia de la integridad, las limitaciones de la integridad se deben especificar por separado de los programas de la aplicación y se almacenan en la base de datos. Debe ser posible cambiar esas limitaciones sin afectar innecesariamente las aplicaciones existentes.
– Regla 11: independencia de la distribución, la distribución de las porciones de la base de datos a las varias localizaciones debe ser invisible a los usuarios de la base de datos. Los usos existentes deben continuar funcionando con éxito:
- Cuando una versión distribuida del SGBD se introdujo por primera vez
- cuando se distribuyen los datos existentes se redistribuyen en todo el sistema.
– Regla 12: la regla de la no subversión, si el sistema proporciona una interfaz de bajo nivel de registro, a parte de una interfaz relacional, que esa interfaz de bajo nivel no se pueda utilizar para subvertir el sistema, por ejemplo: sin pasar por seguridad relacional o limitación de integridad. Esto es debido a que existen sistemas anteriormente no relacionales que añadieron una interfaz relacional, pero con la interfaz nativa existe la posibilidad de trabajar no relacionalmente.
¿Qué es un motor de base de datos?
Un motor de base de datos (o motor de almacenamiento ) es el componente de software subyacente que un sistema de administración de base de datos (DBMS) utiliza para crear, leer, actualizar y eliminar (CRUD) datos de una base de datos . La mayoría de los sistemas de gestión de bases de datos incluyen su propia interfaz de programación de aplicaciones (API) que permite al usuario interactuar con su motor subyacente sin pasar por la interfaz de usuario del DBMS.
El término "motor de base de datos" se usa frecuentemente de manera intercambiable con " servidor de base de datos " o "sistema de gestión de base de datos". Una 'instancia de base de datos' se refiere a los procesos y estructuras de memoria del motor de base de datos en ejecución .
Muchos de los DBMS modernos admiten varios motores de almacenamiento dentro de la misma base de datos. Por ejemplo, MySQL soporta InnoDB así como MyISAM .
Algunos motores de almacenamiento son transaccionales .
| Nombre | Licencia | Transaccional |
|---|---|---|
| Aria | GPL | No |
| Halcón | GPL | Sí |
| InnoDB | GPL | Sí |
| MyISAM | GPL | No |
| InfiniDB | CPL | No |
| TokuDB | GPL | Sí |
| WiredTiger | GPL | Sí |
| XtraDB | GPL | Sí |
| RocksDB | BSD | Sí |
Los tipos de motores adicionales incluyen:
- Motores de base de datos incrustados
- Motores de base de datos en memoria
¿Qué es un SGBD?
Un sistema gestor de base de datos (SGBD) es un conjunto de programas que permiten el almacenamiento, modificación y extracción de la información en una base de datos .Los usuarios pueden acceder a la información usando herramientas específicas de consulta y de generación de informes, o bien mediante aplicaciones al efecto.
Estos sistemas también proporcionan métodos para mantener la integridad de los datos, para administrar el acceso de usuarios a los datos y para recuperar la información si el sistema se corrompe. Permiten presentar la información de la base de datos en variados formatos. La mayoría incluyen un generador de informes. También pueden incluir un módulo gráfico que permita presentar la información con gráficos y tablas.
Generalmente se accede a los datos mediante lenguajes de consulta, lenguajes de alto nivel que simplifican la tarea de construir las aplicaciones. También simplifican las consultas y la presentación de la información. Un SGBD permite controlar el acceso a los datos, asegurar su integridad, gestionar el acceso concurrente a ellos, recuperar los datos tras un fallo del sistema y hacer copias de seguridad. Las bases de datos y los sistemas para su gestión son esenciales para cualquier área de negocio, y deben ser gestionados con esmero.
Bases de datos más utilizadas
Un SGBD debe permitir especificar tipos y estructuras, permite la manipulación de los datos mediante consultas y la actualización de la base de datos de manera sencilla, existen diferentes gestores de bases de datos, pero lo más utilizados son:
MySQL: es uno de los gestores de base de datos más usados, tanto por la comunidad estudiantil como por las empresas, está desarrollada bajo las licencias de GPL y la licencia comercial de Oracle. Este gestor es el más popular de código abierto y es utilizado por Twitter, Facebook y YouTube gracias a su rendimiento y confiabilidad.
SQL Server: está enfocado para entornos empresariales, cuenta con un entorno gráfico para administración, se pueden usar comando DDL Y DML de manera gráfica.
Oracle: es conocido como uno de los gestores de base de datos más completos gracias a su estabilidad y su soporte multiplataforma, este depende del tipo de licencia que se adquiera y se puede usar en distintos sistemas operativos.
Micrososft Acess: este gestor de datos viene incluido en la suite de Microsoft oficce, es de uso fácil, permite crear bases de datos rápidamente, cuenta con plantillas para crear aplicaciones sencillas, pero funcionales, y es especialmente para uso personal de pequeñas organizaciones.
Postgre SQL: es un gestor de base de datos bajo licencia, el desarrollo de este no es manejado por una empresa o persona, es dirigido por una comunidad de desarrolladores. En comparación con otros gestores es lento en actualizaciones y su consumo de recursos es más alto que el de MySQL.
El objetivo principal de estos gestores es hacer más amable la interacción con la base de datos, existen un sinfín de ellos, cada uno con características distintas.
Clasificación de las bases de datos según su variabilidad
o Estáticas:
Éstas son bases de datos de sólo lectura, utilizadas primordialmente para almacenar datos históricos que posteriormente se pueden utilizar para estudiar el comportamiento de un conjunto de datos a través del tiempo, realizar proyecciones y tomar decisiones.
o Dinámicas:
Éstas son bases de datos donde la información almacenada se modifica con el tiempo, permitiendo operaciones como actualización, borrado y adición de datos, además de las operaciones fundamentales de consulta. Un ejemplo de esto puede ser la base de datos utilizada en un sistema de información de una tienda de abarrotes, una farmacia, un videoclub.
Modelos de base de datos
Un modelo de datos jerárquico es un modelo de datos en el cual los datos son organizados en una estructura parecida a un árbol. La estructura permite a la información que se repite y usa relaciones padre/Hijo: cada padre puede tener muchos hijos pero cada hijo sólo tiene un padre. Todos los atributos de un registro específico son catalogados bajo un tipo de entidad.
En una base de datos, un tipo de entidad es el equivalente de una tabla; cada registro individual es representado como una fila y un atributo como una columna. Los tipos de entidad son relacionados el uno con el otro usando 1: Trazar un mapa de n, también conocido como relación de uno a varios. El ejemplo más aprobado de base de datos jerárquica modela es un IMS diseñado por la IBM.de eso
Un ejemplo de un modelo de datos jerárquico sería si una organización tuviera los registros de empleados en una tabla (el tipo de entidad) llamada "Empleados". En la tabla habría atributos/columnas como el Nombre de pila, el Apellido, el Nombre de Trabajo y el Salario. La empresa también tiene datos sobre los hijos del empleado en una tabla separada "Hijos" llamada con atributos como el Nombre de pila, el Apellido, y la fecha de nacimiento. La tabla de Empleado representa un segmento paternal y la tabla de Hijos representa un segmento Infantil. Estos dos segmentos forman una jerarquía donde un empleado puede tener muchos hijos, pero cada hijo sólo puede tener un padre.
Considere la estructura siguiente:
| EmpNo | Puesto | Reporta |
|---|---|---|
| 10 | Director | |
| 20 | Senior Manager | 10 |
| 30 | Typist | 20 |
| 40 | Programmer | 20 |
En esta tabla, "el hijo" es el mismo tipo que "el padre". La jerarquía que declara EmpNo 10 es el jefe de 20, y30 y 40 cada informe a 20 es representado por la columna "Reporta". Llamada en la Base de datos relacional, la columna Reporta es una llave foránea, el referirse de la columna EmpNo. Si el tipo de datos "hijo" fuera diferente, estaría en una tabla diferente, pero todavía habría una llave foránea que se refiere la columna EmpNo de la tabla de empleados.
o Red:
Una base de datos de red es una base de datos conformada por una colección o set de registros, los cuales están conectados entre sí por medio de enlaces en una red. El registro es similar al de una entidad como las empleadas en el modelo relacional.
Un registro es una colección o conjunto de campos (atributos), donde cada uno de ellos contiene solamente un único valor almacenado.
El enlace es exclusivamente la asociación entre dos registros, así que podemos verla como una relación estrictamente binaria.
Una estructura de base de datos de red, llamada algunas veces estructura de plex, abarca más que la estructura de árbol: un nodo hijo en la estructura red puede tener más de un nodo padre. En otras palabras, la restricción de que en un árbol jerárquico cada hijo puede tener sólo un padre, se hace menos severa.
Así, la estructura de árbol se puede considerar como un caso especial de la estructura de red.
o Documental:
Una base de datos documental está constituida por un conjunto de programas que almacenan, recuperan y gestionan datos de documentos o datos de algún modo estructurados. Este tipo de bases de datos constituyen una de las principales subcategorías dentro de las denominadas bases de datos NoSQL. A diferencia de las bases de datos relacionales, estas bases de datos están diseñadas alrededor de una noción abstracta de "Documento".
o Relacional:
El modelo relacional, para el modelado y la gestión de bases de datos, es un modelo de datos basado en la lógica de predicados y en la teoría de conjuntos.
Tras ser postuladas sus bases en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos.
Su idea fundamental es el uso de relaciones. Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados tuplas. Pese a que esta es la teoría de las bases de datos relacionales creadas por Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar, pensando en cada relación como si fuese una tabla que está compuesta por registros (cada fila de la tabla sería un registro o "tupla") y columnas (también llamadas "campos").
Es el modelo más utilizado en la actualidad para modelar problemas reales y administrar datos dinámica mente.
Ventajas
- Provee herramientas que garantizan evitar la duplicidad de registros.
- Garantiza la integridad referencial, así, al eliminar un registro elimina todos los registros relacionados dependientes.
- Favorece la normalización por ser más comprensible y aplicable.
Desventajas
- Presentan deficiencias con datos gráficos, multimedia, CAD y sistemas de información geográfica.
- No se manipulan de forma eficiente los bloques de texto como tipo de dato.
Las bases de datos orientadas a objetos (BDOO) se propusieron con el objetivo de satisfacer las necesidades de las aplicaciones anteriores y así, complementar pero no sustituir a las bases de datos relacionales.
o Orientada a objetos:
En una base de datos orientada a objetos, la información se representa mediante objetos como los presentes en la programación orientada a objetos. Cuando se integra las características de una base de datos con las de un lenguaje de programación orientado a objetos, el resultado es un sistema gestor de base de datos orientada a objetos (ODBMS, object database management system). Un ODBMS hace que los objetos de la base de datos aparezcan como objetos de un lenguaje de programación en uno o más lenguajes de programación a los que dé soporte. Un ODBMS extiende los lenguajes con datos persistentes de forma transparente, control de concurrencia, recuperación de datos, consultas asociativas y otras capacidades.
Las bases de datos orientadas a objetos se diseñan para trabajar bien en conjunción con lenguajes de programación orientados a objetos como Java, C#, Visual Basic.NET y C++. Los ODBMS usan exactamente el mismo modelo que estos lenguajes de programación.
Los ODBMS son una buena elección para aquellos sistemas que necesitan un buen rendimiento en la manipulación de tipos de dato complejos.
Los ODBMS proporcionan los costes de desarrollo más bajos y el mejor rendimiento cuando se usan objetos gracias a que almacenan objetos en disco y tienen una integración transparente con el programa escrito en un lenguaje de programación orientado a objetos, al almacenar exactamente el modelo de objeto usado a nivel aplicativo, lo que reduce los costes de desarrollo y mantenimiento.
Que es una relación y que tipos de relaciones existen
La tabla siguiente describe las relaciones de bases de datos.
| Tipo de relación | Descripción |
|---|---|
| Unívoca |
Las dos tablas pueden tener sólo un registro en cada lado de la relación.
Cada valor de clave primaria se relaciona con sólo un (o ningún) registro en la tabla relacionada.
La mayoría de relaciones unívocas están impuestas por las reglas empresariales y no fluyen con naturalidad a partir de los datos. Sin este tipo de regla, generalmente podrá combinar ambas tablas sin incumplir ninguna regla de normalización.
|
| Uno a varios | La tabla de claves primaria sólo contiene un registro que se relaciona con ninguno, uno o varios registros en la tabla relacionada. |
| Varios a varios | Cada registro en ambas tablas puede estar relacionado con varios registros (o con ninguno) en la otra tabla. Estas relaciones requieren una tercera tabla, denominada tabla de enlace o asociación, porque los sistemas relacionales no pueden alojar directamente la relación. |
En la aplicación Configuración de base de datos, puede definir sentencias SQL (Structured Query Language) para las uniones y crear relaciones entre objetos de nivel superior e inferior. Puede utilizar una unión para vincular datos de varios objetos. El nivel superior es el objeto existente y el nivel inferior es el objeto que crea.
Diseño de base de datos:
Como se define en [NBG01], el modelado de datos conceptuales representa la fase inicial del desarrollo del diseño de los datos permanentes y el almacenamiento de datos permanentes para el sistema. En muchos casos, los datos permanentes para el sistema los gestiona un sistema de gestión de bases de datos relacionales (RDBMS). Las entidades del sistema y empresariales que se identifican en un nivel conceptual de los modelos empresariales y los requisitos del sistema se desarrollarán durante las tareas de análisis de guiones de uso, de diseño de guiones de uso y de diseño de bases de datos hasta convertirse en diseños de tablas físicas detalladas que se implementarán en el RDBMS. Tenga en cuenta que el modelo conceptual de datos que se trata en este documento de conceptos no es un producto de trabajo independiente. Consiste en una vista compuesta de información contenida en productos de trabajo de modelado empresarial, requisitos y disciplinas de análisis y diseño que es importante para el desarrollo del modelo de datos.
El modelo de datos suele evolucionar a través de las tres fases generales siguientes:
o Conceptual:
Esta fase incluye la identificación de las entidades del sistema y empresariales clave de nivel superior y sus relaciones, que definen el ámbito del problema que tratará el sistema. Estas entidades clave del sistema y empresariales se definen mediante la utilización de elementos de modelado del perfil UML para el modelado empresarial, incluidos los elementos del modelo de análisis empresarial y el modelo de clase de análisis del modelo de análisis.
o Lógico:
Esta fase incluye el perfeccionamiento de las entidades del sistema y empresariales de alto nivel de la fase conceptual en entidades lógicas más detalladas. Estas entidades lógicas y sus relaciones se pueden definir, opcionalmente, en un modelo lógico de datos mediante la utilización de los elementos de modelado del perfil UML para el diseño de bases de datos, como se describe en la Directriz: Modelo de datos. Este modelo lógico de datos forma parte del Producto de trabajo: Modelo de datos y no es un producto de trabajo diferente de RUP.
o Físico:
Esta fase incluye la transformación de los diseños de la clase lógica en diseños de tablas de bases de datos físicas detalladas y optimizadas. La fase física también incluye la correlación de los diseños de tablas de base de datos con espacios de tablas y con el componente de base de datos en el diseño de almacenamiento de bases de datos.
- Ventajas
- Provee herramientas que garantizan evitar la duplicidad de registros.
- Garantiza la integridad referencial, así, al eliminar un registro elimina todos los registros relacionados dependientes.
- Favorece la normalización por ser más comprensible y aplicable.
- Desventajas
- Presentan deficiencias con datos gráficos, multimedia, CAD y sistemas de información geográfica.
- No se manipulan de forma manejable los bloques de texto como tipo de dato.
- Las bases de datos orientadas a objetos (BDOO) se propusieron con el objetivo de satisfacer las necesidades de las aplicaciones anteriores y así, complementar pero no sustituir a las bases de datos relacionales.
Elementos de una base de datos relacional:
o Entidad o Tabla:
Son estructuras encargadas de alojar la informacion de la base de datos.
o Campo:
Son cada una de las columnas de una tabla, cada campo almacena un dato en concreto.
o Dato:
- Los datos se organizan en relaciones compuestas por tuplas de atributos. Si convertimos esta definición a tablas tenemos que los datos se organizan en tablas compuestas por filas (registros) y columnas (campos).
o Registro o tupla:
Cada una de las filas de la tabla que agrupa toda la informacion de un mismo elemento.
¿Qué es la normalización?
La normalización de bases de datos es un proceso que consiste en designar y aplicar una serie de reglas a las relaciones obtenidas tras el paso del modelo entidad-relación al modelo relacional.
Las bases de datos relacionales se normalizan para:
- Evitar la redundancia de los datos.
- Disminuir problemas de actualización de los datos en las tablas.
- Proteger la integridad de datos.
En el modelo relacional es frecuente llamar tabla a una relación; para que una tabla sea considerada como una relación tiene que cumplir con algunas restricciones:
- Cada tabla debe tener su nombre único.
- No puede haber dos filas iguales. No se permiten los duplicados.
- Todos los datos en una columna deben ser del mismo tipo.
¿Cuántas formas normales existen?
En la teoría de bases de datos relacionales, las formas normales (NF) proporcionan los criterios para determinar el grado de vulnerabilidad de una tabla a inconsistencias y anomalías lógicas. Cuanto más alta sea la forma normal aplicable a una tabla, menos vulnerable será a inconsistencias y anomalías. Cada tabla tiene una "forma normal más alta" (HNF): por definición, una tabla siempre satisface los requisitos de su HNF y de todas las formas normales más bajas que su HNF; también por definición, una tabla no puede satisfacer los requisitos de ninguna forma normal más arriba que su HNF.
Las formas normales son aplicables a tablas individuales; decir que una base de datos entera está en la forma normal n es decir que todas sus tablas están en la forma normal n.
Los recién llegados al diseño de bases de datos a veces suponen que la normalización procede de una manera iterativa, es decir un diseño 1NF primero se normaliza a 2NF, entonces a 3NF, etcétera. Ésta no es una descripción exacta de cómo la normalización trabaja típicamente. Una tabla sensiblemente diseñada es probable que esté en 3NF en la primera tentativa; además, si está en 3NF, también es extremadamente probable que tenga una forma HNF de 5NF. Conseguir formas normales "más altas" (sobre 3NF) usualmente no requiere un gasto adicional de esfuerzo por parte del diseñador, porque las tablas 3NF usualmente no necesitan ninguna modificación para satisfacer los requisitos de estas formas normales más altas.
Edgar F. Codd originalmente definió las tres primeras formas normales (1NF, 2NF, y 3NF). Estas formas normales se han resumido como requiriendo que todos los atributos no-clave sean dependientes en "la clave, la clave completa, y nada excepto la clave". Las cuarta y quinta formas normales (4NF y 5NF) se ocupan específicamente de la representación de las relaciones muchos a muchos y uno muchos entre los atributos. La sexta forma normal (6NF), en pocas palabras, se basa en el principio de que si se tiene más de dos claves candidatas en una tabla, se tendrán que crear otras tablas con estas.
Por ejemplo si tenemos "ítem" con un id código de producto y con los atributos descripción y precio que son claves candidatas se tendría que crear otras tablas separando la tabla ítem: ItemDesc {código_producto*, Descripción} ItemPrecio {código_producto*, Precio}.
La sexta forma normal no es muy utilizada porque genera más tablas cuando tenemos pequeñas bases de datos.
Primera forma normal
La primera forma normal (1FN o forma mínima) es forma normal usada en normalización de bases de datos. Una tabla de base de datos relacional que se adhiere a la 1FN es una que satisface cierto conjunto mínimo de criterios. Estos criterios se refieren básicamente a asegurarse que la tabla es una representación fiel de una relación1 y está libre de "grupos repetitivos".2

Segunda forma normal
La segunda forma normal (2NF) es una forma normal usada en normalización de bases de datos. La 2NF fue definida originalmente por E.F. Codd1 en 1971. Una tabla que está en la primera forma normal (1NF) debe satisfacer criterios adicionales para calificar para la segunda forma normal. Específicamente: una tabla 1NF está en 2NF si y solo si, dada una clave primaria y cualquier atributo que no sea un constituyente de la clave primaria, el atributo no clave depende de toda la clave primaria en vez de solo de una parte de ella.
En términos levemente más formales: una tabla 1NF está en 2NF si y solo si ninguno de sus atributos no-principales son funcionalmente dependientes en una parte (subconjunto propio) de una clave candidata (Un atributo no-principal es uno que no pertenece a ninguna clave candidata).
Observa que cuando una tabla 1NF no tiene ninguna clave candidata compuesta (claves candidatas consisten en más de un atributo), la tabla está automáticamente en 2NF.

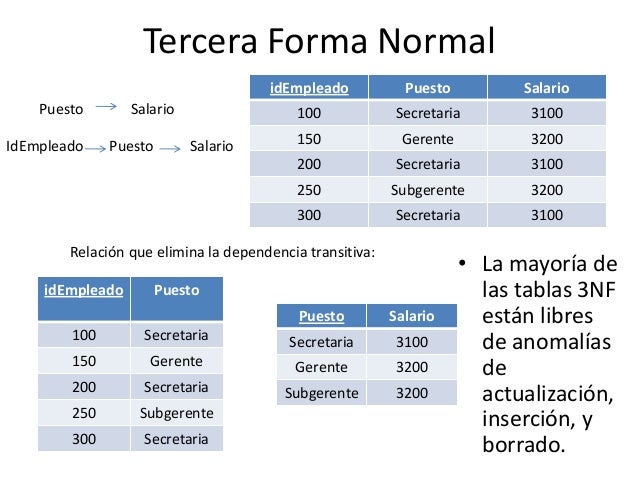
Tercera forma normal
La tercera forma normal (3NF) es una forma normal usada en la normalización de bases de datos. La 3NF fue definida originalmente por E.F. Codd1 en 1971. La definición de Codd indica que una tabla está en 3NF si y solo si las tres condiciones siguientes se cumplen:
- La tabla está en la segunda forma normal (2NF)
- Ningún atributo no-primario de la tabla es dependiente transitivamente de una clave primaria
- Es una relación que no incluye ningún atributo clave
Un atributo no-primario es un atributo que no pertenece a ninguna clave candidata. Una dependencia transitiva es una dependencia funcional X → Z en la cual Z no es inmediatamente dependiente de X, pero sí de un tercer conjunto de atributos Y, que a su vez depende de X. Es decir, X → Z por virtud de X → Y e Y → Z.
Una formulación alternativa de la definición de Codd, dada por Carlo Zaniolo2 en 1982, es ésta: Una tabla está en 3NF si y solo si, para cada una de sus dependencias funcionales X → A, por lo menos una de las condiciones siguientes se mantiene:
- X contiene A, ó
- X es una superclave, ó
- A es un atributo primario (es decir, A está contenido dentro de una clave candidata)
La definición de Zaniolo tiene la ventaja de dar un claro sentido de la diferencia entre la 3NF y la más rigurosa forma normal de Boyce-Codd (BCNF). La CONFÍN simplemente elimina la tercera alternativa ("A es un atributo primario"
Forma normal de Boyce-Codd
La Forma Normal de Boyce-Codd (o FNBC) es una forma normal utilizada en la normalización de bases de datos. Es una versión ligeramente más fuerte de la Tercera forma normal (3FN).1 La forma normal de Boyce-Codd requiere que no existan dependencias funcionales no triviales de los atributos que no sean un conjunto de la clave candidata. En una tabla en 3FN, todos los atributos dependen de una clave, de la clave completa y de ninguna otra cosa excepto de la clave (excluyendo dependencias triviales, como ). Se dice que una tabla está en FNBC si y solo si está en 3FN y cada dependencia funcional no trivial tiene una clave candidata como determinante. En términos menos formales, una tabla está en FNBC si está en 3FN y los únicos determinantes son claves candidatas.

Cuarta forma normal
La cuarta forma normal (4NF) es una forma normal usada en la normalización de bases de datos. La 4NF se asegura de que las dependencias multivaluadas independientes estén correctas y eficientemente representadas en un diseño de base de datos. La 4NF es el siguiente nivel de normalización después de la forma normal de Boyce-Codd (BCNF).

Quinta forma normal
La quinta forma normal (5FN), también conocida como forma normal de proyección-unión (PJ/NF), es un nivel de normalización de bases de datos diseñado para reducir redundancia en las bases de datos relacionales que guardan hechos multi-valores aislando semánticamente relaciones múltiples relacionadas. Una tabla se dice que está en 5NF si y sólo si está en 4NF y cada dependencia de unión (join) en ella es implicada por las claves candidatas.
La quinta forma normal fue definida por Ronald Fagin en su contribución al congreso "Normal forms and relational database operators" de 19791
Forma normal de dominio/clave
La forma normal de dominio/clave (DKNF) es una forma normal usada en normalización de bases de datos que requiere que la base de datos contenga restricciones de dominios y de claves.
Una restricción del dominio especifica los valores permitidos para un atributo dado, mientras que una restricción clave especifica los atributos que identifican únicamente una fila en una tabla dada.
Esta es el santo grial de la Base de datos y es alcanzado cuando cada restricción en la relación es una consecuencia lógica de la definición de claves y dominios, y, haciendo cumplir las restricciones y condiciones de la clave y del dominio, causa que sean satisfechas todas las restricciones. Así, esto evita todas las anomalías no-temporales.
Es mucho más fácil construir una base de datos en forma normal de dominio/clave que convertir pequeñas bases de datos que puedan contener numerosas anomalías. Sin embargo, construir con éxito una base de datos en forma normal de dominio/clave sigue siendo una tarea difícil, incluso para programadores experimentados de bases de datos. Así, mientras que la forma normal de dominio/clave elimina los problemas encontrados en la mayoría de las bases de datos, tiende para ser la forma normal más costosa de alcanzar. Sin embargo, el no poder alcanzar la forma normal de dominio/clave puede llevar costos ocultos a largo plazo, debido a anomalías que aparecen con el tiempo en las bases de datos que solamente se adhieren a formas normales más bajas.
¿Qué es SQL?
SQL (por sus siglas en inglés Structured Query Language; en españollenguaje de consulta estructurada) es un lenguaje específico del dominio utilizado en programación, diseñado para administrar, y recuperar información de sistemas de gestión de bases de datos relacionales1. Una de sus principales características es el manejo del álgebra y el cálculo relacional para efectuar consultas con el fin de recuperar, de forma sencilla, información de bases de datos, así como realizar cambios en ellas.
Originalmente basado en el álgebra relacional y en el cálculo relacional, SQL consiste en un lenguaje de definición de datos, un lenguaje de manipulación de datos y un lenguaje de control de datos. El alcance de SQL incluye la inserción de datos, consultas, actualizaciones y borrado, la creación y modificación de esquemas y el control de acceso a los datos. También el SQL a veces se describe como un lenguaje declarativo, también incluye elementos procesales.
SQL fue uno de los primeros lenguajes comerciales para el modelo relacional de Edgar Frank Codd como se describió en su artículo de investigación de 1970 El modelo relacional de datos para grandes bancos de datos compartidos. A pesar de no adherirse totalmente al modelo relacional descrito por Codd, pasó a ser el lenguaje de base de datos más usado.
SQL pasó a ser el estándar del Instituto Nacional Estadounidense de Estándares (ANSI) en 1986 y de la Organización Internacional de Normalización (ISO) en 1987. Desde entonces, el estándar ha sido revisado para incluir más características. A pesar de la existencia de ambos estándares, la mayoría de los códigos SQL no son completamente portables entre sistemas de bases de datos diferentes sin ajustes.
Lenguaje de definición de datos (DDL):
Las sentencias DDL se utilizan para crear y modificar la estructura de las tablas así como otros objetos de la base de datos.
- CREATE - para crear objetos en la base de datos.
- ALTER - modifica la estructura de la base de datos.
- DROP - borra objetos de la base de datos.
- TRUNCATE - elimina todos los registros de la tabla, incluyendo todos los espacios asignados a los registros.
Lenguaje de manipulación de datos (DML)
Las sentencias de lenguaje de manipulación de datos (DML) son utilizadas para gestionar datos dentro de los schemas. Algunos ejemplos:
- SELECT - para obtener datos de una base de datos.
- INSERT - para insertar datos a una tabla.
- UPDATE - para modificar datos existentes dentro de una tabla.
- DELETE - elimina todos los registros de la tabla; no borra los espacios asignados a los registros.
DCL (Data Control Language):
Permite crear roles, permisos e integridad referencial, así como el control al acceso a la base de datos.
- GRANT: Usado para otorgar privilegios de acceso de usuario a la base de datos.
- REVOKE: Utilizado para retirar privilegios de acceso otorgados con el comando GRANT.
TCL (Transactional Control Language):
Permite administrar diferentes transacciones que ocurren dentro de una base de datos.
- COMMIT: Empleado para guardar el trabajo hecho.
- ROLLBACK: Utilizado para deshacer la modificación que hice desde el último COMMIT.
¿Qué es ACID?
En bases de datos se denomina ACID a las características de los parámetros que permiten clasificar las transaccionesde los sistemas de gestión de bases de datos. Cuando se dice que es ACID compliant se indica -en diversos grados- que éste permite realizar transacciones.
En concreto ACID es un acrónimo de Atomicity, Consistency, Isolation and Durability: Atomicidad, Consistencia, Aislamiento y Durabilidad en español.
- Atomicidad: Si cuando una operación consiste en una serie de pasos, bien todos ellos se ejecutan o bien ninguno, es decir, las transacciones son completas.
- Consistencia: (Integridad). Es la propiedad que asegura que sólo se empieza aquello que se puede acabar. Por lo tanto se ejecutan aquellas operaciones que no van a romper las reglas y directrices de Integridad de la base de datos. La propiedad de consistencia sostiene que cualquier transacción llevará a la base de datos desde un estado válido a otro también válido. "La Integridad de la Base de Datos nos permite asegurar que los datos son exactos y consistentes, es decir que estén siempre intactos, sean siempre los esperados y que de ninguna manera cambian ni se deformen. De esta manera podemos garantizar que la información que se presenta al usuario será siempre la misma."
- Aislamiento: Esta propiedad asegura que una operación no puede afectar a otras. Esto asegura que la realización de dos transacciones sobre la misma información sean independientes y no generen ningún tipo de error. Esta propiedad define cómo y cuándo los cambios producidos por una operación se hacen visibles para las demás operaciones concurrentes. El aislamiento puede alcanzarse en distintos niveles, siendo el parámetro esencial a la hora de seleccionar SGBDs.
- Durabilidad: (Persistencia). Esta propiedad asegura que una vez realizada la operación, esta persistirá y no se podrá deshacer aunque falle el sistema y que de esta forma los datos sobrevivan de alguna manera.
Cumpliendo estos 4 requisitos un sistema gestor de bases de datos puede ser considerado ACID Compliant.
¿Qué es cloud computing?
El mundo del software está en constante cambio y evolución. Cuando Salesforce fue creada, en 1999, se trataba del primer servicio empresarial a ofrecer aplicaciones de negocios en un sitio web, que acabó por ser llamado por el mercado de computación en la nube, o cloud computing. Desde entonces, Salesforce ha sido la pionera en este tipo de servicio para pequeñas, medianas y grandes empresas.
En otras palabras, la definición de cloud computing es ofrecer servicios a través de la conectividad y gran escala de Internet. La computación en la nube democratiza el acceso a recursos de software de nivel internacional, pues es una aplicación de software que atiende a diversos clientes. La multilocación es lo que diferencia la computación en la nube de la simple tercerización y de modelos de proveedores de servicios de aplicaciones más antiguos. Ahora, las pequeñas empresas tienen la capacidad de dominar el poder de la tecnología avanzada de manera escalable.
La computación en la nube ofrece a los individuos y a las empresas de todos los tamaños la capacidad de un pool de recursos de computación con buen mantenimiento, seguro, de fácil acceso y bajo demanda, como servidores, almacenamiento de datos y solución de aplicaciones. Eso proporciona a las empresas mayor flexibilidad en relación a sus datos e informaciones, que se pueden acceder en cualquier lugar y hora, siendo esencial para empresas con sedes alrededor del mundo o en distintos ambientes de trabajo. Con un mínimo de gestión, todos los elementos de software de la computación en la nube pueden ser dimensionados bajo demanda, usted solo necesita conexión a Internet.
¿Qué es big data?
Big data es un término que describe el gran volumen de datos – estructurados y no estructurados – que inundan una empresa todos los días. Pero no es la cantidad de datos lo importante. Lo que importa es lo que las organizaciones hacen con los datos. El big data puede ser analizado para obtener insights que conlleven a mejores decisiones y acciones de negocios estratégicas.
Comentarios
Publicar un comentario